Data analysis tools are used to perform complex analysis of data.They will normally have a rich set of analytic functions,which allow sophisticated analysis of data.These tools are designed for buisness analysis.
Data analysis tools can again subdivided into MOLAP tools and ROLAP tools.They came into existence because the term OLAP(On-Line Analytical Processing)has become an industry buzzword.
On-Line Analytical Processing is a decision support software that allows the user to quickly analyze information that has been summarized into multidimensional views and hierarchies.
On Line – Emphasizes live access to data, not static reporting
Analytical Processing – Ad-hoc queries, drill-down, roll-up, reporting across various dimension.
OLAP databases are also known as multidimensional databases or MDDBs.
Multidimensional analysis is a technique whereby data can be analyzed in many dimensions at once.The term dimension here means an attribute such as cost,duration or name.They are equivalent to a column in a relational table.The idea is that instead of analyzing the data in a two-dimensional table,the data is loaded into a multidimensional hypercube to be analyzed.
MOLAP(Multidimensional OLAP) tools have an SQL interface that allows them to extract data from a relational database.On a predefined set of data,MOLAP gives userfriendly,fast access to poweful analytical and statistical functions.They are good to use for analyzing aggregated data with the dimension data.It do very well in dimensional slicing.if data has been loaded into the cube dimensioned by office,region,sales-quantity,sales-value and product,the tool will be able to switch from displaying data by region to displaying data by product or by sales-value.
ROLAP(Relational OLAP) are the traditional SQL-oriented tools that have tight integration to the relational model.They are changing all the time.They use metadata to isolate the user from the complexities of the data warehouse,and to present a buisness perspective of the data.They can be used as data browsers,and will have good drill-down capability from aggregation to detailed data.
Tuesday, December 15, 2009
Operational Data Store(ODS)
An operational data store (ODS) is a type of database that's often used as an interim logical area for a data warehouse.ODS was meant to serve as the point of integration for operational systems.
For example,Banks had several independent systems-loans,checking accounts,saving accounts and so on..The teller support computers and ATM helped push many banks to create an ODS to integrate current balances and recent history from these seperate accounts under one customer number.
ODS can be used for integrating disparate data from multiple sources so that business operations, analysis and reporting can be carried out while business operations are occurring. This is the place where most of the data used in current operation is housed before it's transferred to the data warehouse for longer term storage or archiving.
An ODS is designed for relatively simple queries on small amounts of data (such as finding the status of a customer order), rather than the complex queries on large amounts of data typical of the data warehouse.
ODS
For example,Banks had several independent systems-loans,checking accounts,saving accounts and so on..The teller support computers and ATM helped push many banks to create an ODS to integrate current balances and recent history from these seperate accounts under one customer number.
ODS can be used for integrating disparate data from multiple sources so that business operations, analysis and reporting can be carried out while business operations are occurring. This is the place where most of the data used in current operation is housed before it's transferred to the data warehouse for longer term storage or archiving.
An ODS is designed for relatively simple queries on small amounts of data (such as finding the status of a customer order), rather than the complex queries on large amounts of data typical of the data warehouse.
ODS
- provides recent data
- Detailed and lightly summarized data
- Subject-oriented
- Homogeneous
- Support day-to-day decisions & operational activities
- Individual records, transaction or analysis driven
Monday, December 14, 2009
Data Modelling in Data warehousing Part 2
In Data warehouse,We process large amount of data and very few updates or deletes.
The data warehouse has mixed modeling approach of relational modeling and dimensional modeling.
Relational Modeling or Entity-Relationship Modeling is used to illuminate the microscopic relationships among data elements.It removes data redundancy.It makes transaction processing very simple and deterministic.It is more suited for Traditional modeling technique, OLTP and corporate data warehouse.But for the enterprise needs,it become more complex.End users cannot understand or remember an ER model.So the dimensional model comes into picture.
From data warehouse,it is moved to Data mart which is specific to a business process. The data here is kept in denormalized form. It is mostly in dimensional model or flat model..From data mart the reports are created or the data can be pulled by OLAP system for reporting.
Dimensional modeling approach is
The data warehouse has mixed modeling approach of relational modeling and dimensional modeling.
Relational Modeling or Entity-Relationship Modeling is used to illuminate the microscopic relationships among data elements.It removes data redundancy.It makes transaction processing very simple and deterministic.It is more suited for Traditional modeling technique, OLTP and corporate data warehouse.But for the enterprise needs,it become more complex.End users cannot understand or remember an ER model.So the dimensional model comes into picture.
From data warehouse,it is moved to Data mart which is specific to a business process. The data here is kept in denormalized form. It is mostly in dimensional model or flat model..From data mart the reports are created or the data can be pulled by OLAP system for reporting.
Dimensional modeling approach is
- best way to model decision support data.
- only technique for delivering data to end users in a data warehouse.
- a logical design technique that seeks to present the data in a standard framework.
Sunday, December 13, 2009
Data Modelling Basics Part 1
Data Modeling is a process by which the enterprise business model is defined in terms of data elements and the relationships existing among those data elements.
There are three types of data models.
1)The conceptual model mostly suits business people.
2)The logical model which is derived from the conceptual model. It suits designers. It contains entity and attributes details.
3)The physical model which is derived from the Logical model. This mostly suits the Implementers. It is database specific.The level of abstraction is highly specific.
There are three types of data models.
1)The conceptual model mostly suits business people.
2)The logical model which is derived from the conceptual model. It suits designers. It contains entity and attributes details.
3)The physical model which is derived from the Logical model. This mostly suits the Implementers. It is database specific.The level of abstraction is highly specific.
Thursday, December 10, 2009
Data Mart
Data Mart is "Subject or Application Oriented Business View of Warehouse". It is a subset of the information content of a data warehouse that is stored in its own database,summarized or in detail. It is a repository for data to be used as a source for business intelligence. It is not used as part of day-to-day operations. Instead, the data mart periodically receives data from the online transactional processing (OLTP) systems. The data in the data mart is then made available to Analysis Services for creating cubes with preprocessed aggregates. A data mart is made up of measures, dimensions organized in hierarchies, and attributes. Once data is organized, build the database structure for the data mart using either a star or snowflake schema.In simple terms, DataMart's are
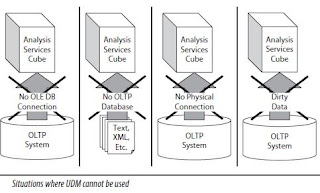
UDM (Unified Data Modelling) makes it possible for business intelligence to be extracted right from the OLTP systems in a manner that does not put undue stress on these systems, thus eliminating the need for data marts. But there are situations still exist where a data mart may be the best choice as a source for business intelligence data.
It is very difficult in practice to operationally support more than a handful of datamarts.so data warehousing comes into picture.Data warehouse is enterprise wide.It captures detailed data for the enterprise and is flexible used for ad-hoc query / analysis requirements. It has very few summary data. The data is kept in most granular form so it can be summarized later as per need.When using data marts,always design the data warehouse for full data retention,and consider storing data in archive until a requirement to analyze all the detailed data exists.
Source: Delivering Business Intelligence with Microsoft SQL Server 2012 (3rd Edition) Author: Brian Larson
.
- Quick Solution to a specific Business Problem
- can be used in Finance, Manufacturing, Sales etc.
- Smaller amount of data in datamarts can be used for Analytic Processing
UDM (Unified Data Modelling) makes it possible for business intelligence to be extracted right from the OLTP systems in a manner that does not put undue stress on these systems, thus eliminating the need for data marts. But there are situations still exist where a data mart may be the best choice as a source for business intelligence data.

It is very difficult in practice to operationally support more than a handful of datamarts.so data warehousing comes into picture.Data warehouse is enterprise wide.It captures detailed data for the enterprise and is flexible used for ad-hoc query / analysis requirements. It has very few summary data. The data is kept in most granular form so it can be summarized later as per need.When using data marts,always design the data warehouse for full data retention,and consider storing data in archive until a requirement to analyze all the detailed data exists.
Source: Delivering Business Intelligence with Microsoft SQL Server 2012 (3rd Edition) Author: Brian Larson
.
Wednesday, December 9, 2009
Importance of Metadata in DWH
Metadata is data about data.The word meta comes from Greek and means among,beside or after.It is like a card index describing how information is structured within data warehouse.Meta data is not only technical data, which describes dimensions and facts, but also data, which describes the warehouse process (ETL), and, most important, “political” data like target groups, stakeholders, team members, and other important people.
Metadata is used for a variety of purposes.
As a part of extracting and loading,it is used to map data sources to the common view of information within DWH.(data transformation and load)
As a part of warehouse management process,it is used to automate the production of summary tables.(data management)
As a part of query management process,it is used to direct a query to the appropriate data source.(query generation)
Metadata is required to describe the data as it resides in DWH. Every object in database needs to be described.Metadata is needed for :
Aggregations are a special case of tables and they require the following metadata to be stored.
The important Metadata goals are:
1)business term definition
2)business rule definition
3)enforcement of information consistency
Eg:

Metadata is used for a variety of purposes.
As a part of extracting and loading,it is used to map data sources to the common view of information within DWH.(data transformation and load)
As a part of warehouse management process,it is used to automate the production of summary tables.(data management)
As a part of query management process,it is used to direct a query to the appropriate data source.(query generation)
Metadata is required to describe the data as it resides in DWH. Every object in database needs to be described.Metadata is needed for :
- tables
- indexes
- views
- constraints
Aggregations are a special case of tables and they require the following metadata to be stored.
- aggregation(table name)
- aggregation_name
- columns
The important Metadata goals are:
1)business term definition
2)business rule definition
3)enforcement of information consistency
Eg:
Descriptions of the properties or characteristics of the data, including data types, field sizes, allowable values, and documentation
•Data about the data
•Data about the database structure
•Security and access rules
Eg:

Data Dictionary Storage
Data dictionary(also called system catalog) stores metadata: that is, data about data, such as
User and accounting information, including passwords
Statistical and descriptive data
Data dictionary(also called system catalog) stores metadata: that is, data about data, such as
- Information about relations
- names of relations
- names and types of attributes of each relation
- names and definitions of views
- integrity constraints
- number of tuples in each relation
- Physical file organization information
- How relation is stored (sequential/hash/heap)
- Physical location of relation
- Information about indices
Data warehouse schemas
Two important Data warehouse schemas are
1)star schema
2)snowflake schema
Before knowing these schemas,we have to know facts and dimensions.Let me start with an example of retail sales analysis data warehouse.
sales transactions-Fact.
customer,locations,suppliers,products and time are Dimensions.
Fact data is the major database component of a typical data warehouse,constituting around 70% of total database volume.It represents a physical transaction that has occured at a point of time and can change during the life of a data warehouse.
Dimension data will change over time.This may be due to changes in buisness,such as regional reorganization.It is designed to minimize the cost of change and is very low volume data.
It means the central factual transaction table is fact table and the surrounding reference tables are dimension tables.Putting them together and can imagine them representing as star;hence the name star schema.It is used to model the multiple dimensions of warehouse data (in contrast to the two-dimensional representation of normal relational schemas).
A variant of the star schema, called snowflake schema , is commonly used to explicitly represent the dimensional hierarchies by normalizing the dimension tables.A more natural way to consider multidimensionality of warehouse data is provided by the multidimensional data model. Thereby, the data cube is the basic underlying modeling construct. Special operations like pivoting (rotate the cube), slicing- dicing (select a subset of the cube), drill-up and drill-down (increasing and decreasing the level of aggregation) have been proposed in this context.
1)star schema
2)snowflake schema
Before knowing these schemas,we have to know facts and dimensions.Let me start with an example of retail sales analysis data warehouse.
sales transactions-Fact.
customer,locations,suppliers,products and time are Dimensions.
Fact data is the major database component of a typical data warehouse,constituting around 70% of total database volume.It represents a physical transaction that has occured at a point of time and can change during the life of a data warehouse.
Dimension data will change over time.This may be due to changes in buisness,such as regional reorganization.It is designed to minimize the cost of change and is very low volume data.
It means the central factual transaction table is fact table and the surrounding reference tables are dimension tables.Putting them together and can imagine them representing as star;hence the name star schema.It is used to model the multiple dimensions of warehouse data (in contrast to the two-dimensional representation of normal relational schemas).
A variant of the star schema, called snowflake schema , is commonly used to explicitly represent the dimensional hierarchies by normalizing the dimension tables.A more natural way to consider multidimensionality of warehouse data is provided by the multidimensional data model. Thereby, the data cube is the basic underlying modeling construct. Special operations like pivoting (rotate the cube), slicing- dicing (select a subset of the cube), drill-up and drill-down (increasing and decreasing the level of aggregation) have been proposed in this context.
Architecture of DWH
DWH must be architected to support 3 major driving factors:
1)populating the warehouse
2)day-to-day management of the warehouse
3)the ability to cope with requirements evolution
The processes in DWH are extract and load process,clean and transform data,back up and archieve dat,manage queries and direct to appropriate data sources.
Extract data from the source systems,load it into database after cleaning (remove the unwanted or irrelavant data).ie..ETL-Extract,Transform and Load.Extract and Loading is done by Load Managers,cleaning ,transforming,backup and archiving by warehouse manager,query management by query manager.
1)populating the warehouse
2)day-to-day management of the warehouse
3)the ability to cope with requirements evolution
The processes in DWH are extract and load process,clean and transform data,back up and archieve dat,manage queries and direct to appropriate data sources.
Extract data from the source systems,load it into database after cleaning (remove the unwanted or irrelavant data).ie..ETL-Extract,Transform and Load.Extract and Loading is done by Load Managers,cleaning ,transforming,backup and archiving by warehouse manager,query management by query manager.
What is a Data Warehouse?
A Data warehouse is a collection of information used to manage and direct the buisness for the most profitable outcome.it is the data(meta/fact/dimension/aggregation) and the process managers(load/warehouse/query) that make information available,enabling people to make informed decisions.
Why Do We Need A Data Warehouse ?
We Can Only
See - What We
Can See !
It is BETTER,FASTER,CHEAPER,Subject Oriented,Integrated,Time Variant & Non-volatile.
It
1)Produce Reports For Long Term Trend Analysis
2)Produce Reports Aggregating Enterprise Data
3)Produce Reports of Multiple Dimensions
Mainly Technical architects,system engineers,database designers,dba's,system managers,operating managers and project managers are using DWH.
Why Do We Need A Data Warehouse ?
We Can Only
See - What We
Can See !
It is BETTER,FASTER,CHEAPER,Subject Oriented,Integrated,Time Variant & Non-volatile.
It
1)Produce Reports For Long Term Trend Analysis
2)Produce Reports Aggregating Enterprise Data
3)Produce Reports of Multiple Dimensions
Mainly Technical architects,system engineers,database designers,dba's,system managers,operating managers and project managers are using DWH.
Subscribe to:
Posts (Atom)

-
 Common BI queries Relational queries Vs OLAP queries Before moving to terms used in Data warehouse, let us see the architect...
Common BI queries Relational queries Vs OLAP queries Before moving to terms used in Data warehouse, let us see the architect... -
From yesterday onwards, I am stuck up with an error while trying to deploy cube. " You cannot deploy the model because the localhost ...
-
 CRM Involves managing all aspects of a customer’s relationship with an organization to increase customer loyalty and retention and an organ...
CRM Involves managing all aspects of a customer’s relationship with an organization to increase customer loyalty and retention and an organ...